G. Jagiella | ostatnia modyfikacja: 03.04.2022 |
W poprzednich rozdziałach opisaliśmy listy łączone oraz przyjrzeliśmy się na laboratoriach ich modyfikacji w postaci list obustronnie łączonych (list dwukierunkowych). Listy łączone to najprostsze z tzw. łączonych struktur danych, których uogólnieniem są m.in. grafy. W tym rozdziale opiszemy szczególny rodzaj grafów: drzewa, ze szczególnym uwzględnieniem drzew binarnych. Zastosujemy je do implementacji drzew przechowujących i wyliczających wyrażenia arytmetyczne, oraz tzw. binarnych drzew wyszukiwań.
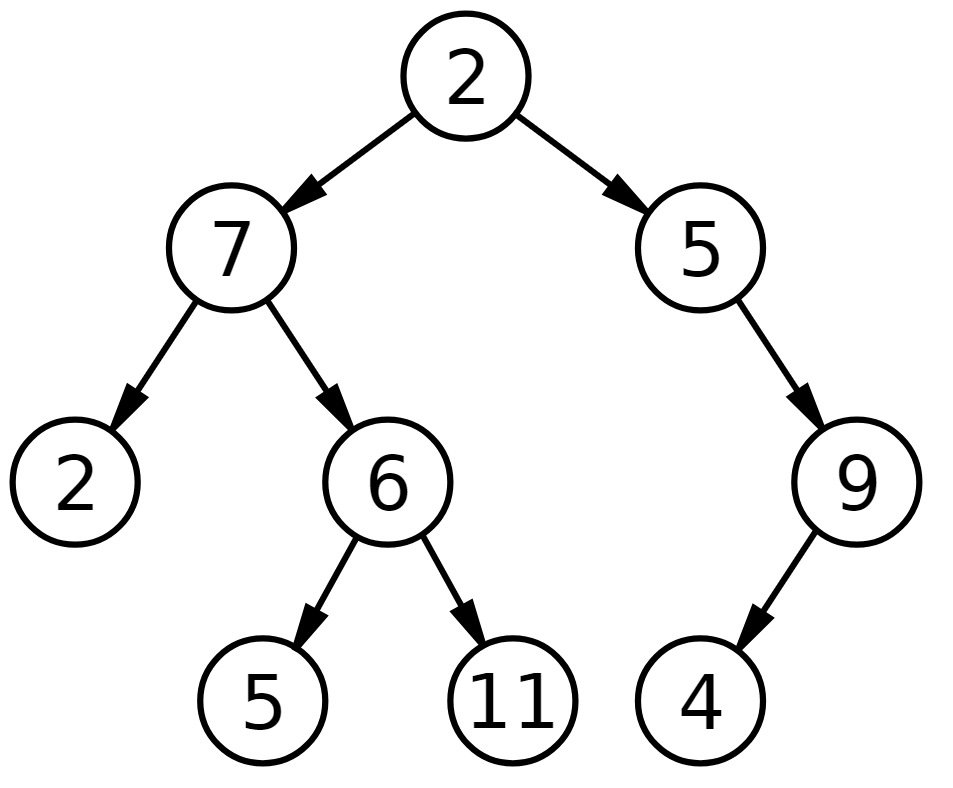
Drzewo to struktura danych w której - podobnie jak dla listy łączonej - dane przechowywane są w węzłach. W odróżnieniu od listy łączonej, każdy węzeł drzewa może pamiętać dowolną ilość następników, nadając całej strukturze (wszystkim jej węzłom) hierarchiczny kształt przypominający drzewo. Rysunek poniżej pokazuje przykład drzewa: strzałki oznaczają w nim, że węzeł wskazywany jest pamiętany przez węzeł, z którego wychodzi strzałka:
Wprowadzimy teraz matematyczny opis drzew i związane z nimi nazewnictwo.
Niech $V$ będzie skończonym zbiorem węzłów z relacją $S$. Gdy dla węzłów $x, y$, zachodzi $x S y$ mówimy, że $y$ jest dzieckiem $x$. Wprowadzamy następujące terminy:
Definicja. Para $(V, S)$ jest drzewem, gdy spełnia następujące warunki:
- W $V$ jest dokładnie jeden korzeń $r$.
- Dla każdego węzła $x \in V$ istnieje dokładnie jedna ścieżka z $r$ do $x$.
Wprost z definicji wynika, że jeśli $(V,S)$ jest drzewem, to każdy węzeł z $V$ z wyjątkiem korzenia posiada dokładnie jednego rodzica.
Poniżej kilka przykładów użycia drzew do reprezentacji różnych danych:
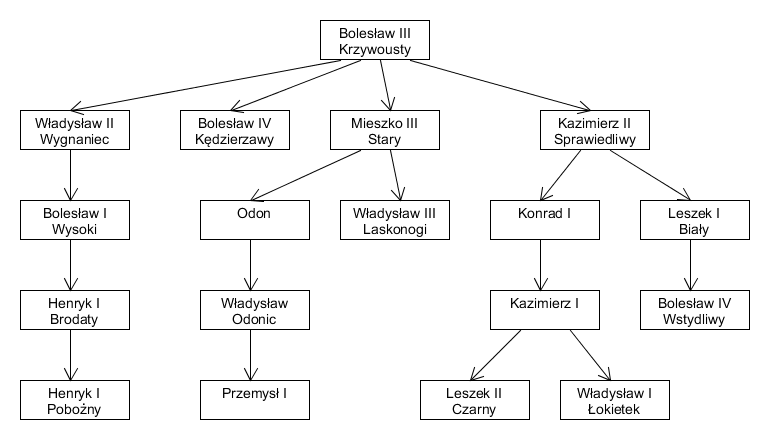
Przykład 1. Szczególny rodzaj drzewa genealogicznego, w którym za wierzchołki przyjmujemy wybranych potomków osoby w linii zgodnej z płcią tej osoby:
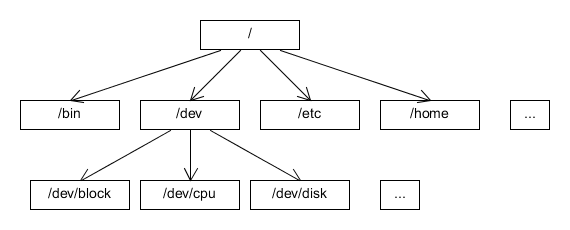
Przykład 2. Struktura katalogów na dysku (bardzo niepełny obraz):
Przykład 3. Drzewa filogenetyczne - diagramy [najbliższych] wspólnych przodków:
Źródło obrazu: Wikipedia.org, na licencji Creative Commons
Drzewa zazwyczaj rysujemy korzeniem do góry - liście umieszczamy na dole (przykład 3 powyżej jest wyjątkiem).
Wprowadźmy dodatkowe nazewnictwo dotyczące drzew:
Przykładowe poddrzewo $V_x$, gdzie $x$ to prawe dziecko korzenia:
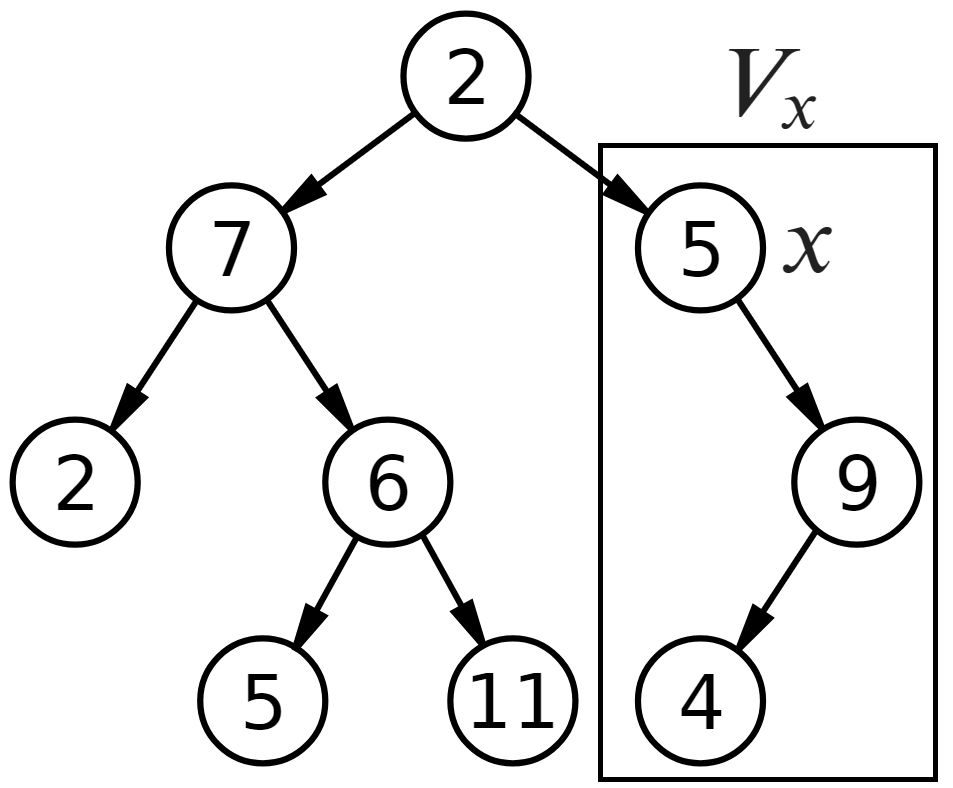
Fakt 1. Niech $V$ będzie drzewem o korzeniu $r$. Wtedy:
- $V_x$ jest drzewem o korzeniu $x$.
- Drzewo $V$ jest swoim własnym poddrzewem ($V$ = $V_r$).
- Poddrzewo poddrzewa $V$ jest poddrzewem $V$.
- Jeśli $W$ jest poddrzewem $W'$ i $W'$ jest poddrzewem $W$, to $W = W'$.
Z Faktu wynika, że relacja bycia poddrzewem jest zwrotna (2.), tranzytywna (3.) i słabo antysymetryczna (4.), czyli jest porządkiem częściowym. Elementem największym tego porządku jest całe drzewo (1.).
Drzewem binarnym nazywamy takie drzewo, w którym każdy węzeł ma co najwyżej dwa dziecka, i spośród nich co najwyżej jedno jest lewym dzieckiem i co najwyżej jedno jest prawym dzieckiem.
Bardziej formalnie, na drzewie $V$ istnieją dodatkowe relacje $L$i $R$ (dla lewego i prawego dziecka odpowiednio) takie, że że dla wszystkich $x, y \in V$, $$x S y \iff x L y ~ \overline{\vee} ~ x R y,$$ (gdzie $\overline{\vee}$ oznacza alternatywę wykluczającą), oraz dla każdego $x$ istnieje co najwyżej jeden $y$ taki, że $x L y$ oraz co najwyżej jeden $y'$ taki, że $x R y'$. Oznacza to, że dziecko każdego węzła jest albo jego lewym dzieckiem, albo jego prawym dzieckiem. Zwracamy tu uwagę, że w zwykłym (niebinarnym) drzewie nie rozróżniamy kolejności wśród dziecek węzła.
Przykładem drzewa binarnego jest drzewo z początku rozdziału. W drzewie binarnym, rysując lewe lub prawe dziecko węzła, umieszczamy je z odpowiedniej strony pod tym węzłem. Zwracamy uwagę, że węzeł może mieć prawe dziecko, lecz nie mieć lewego dziecka (takim węzłem na drzewie z początku rozdziału jest węzeł z liczbą 5).
Z uwagi na rozróżnienie lewego i prawego dziecka danego węzła, można jednoznacznie określić pojęcia jego lewego oraz prawego poddrzewa:
To pozwala nam na inny opis drzew binarnych. Drzewo takie można rekurencyjnie opisać jako następującą trójkę obiektów:
Z takiego opisu drzewa będzie korzystać implementacja drzew binarnych: klasa BinaryTree. Wewnętrznie, instancje tej klasy będą używały trzech artybutów:
key - obiekt przechowany w korzeniu drzewa.left - instancja BinaryTree reprezentująca lewe poddrzewo, lub None, jeśli lewe poddrzewo nie istnieje.right - instancja BinaryTree reprezentująca prawe poddrzewo, lub None, jeśli prawe poddrzewo nie istnieje.O klasie BinaryTree można również myśleć jako o pojedynczym węźle drzewa binarnego: wtedy key jest obiektem przechowywanym w tym węźle, left jego lewym dzieckiem (lub None), a right jest prawym dzieckiem (lub None).
Początkową wartość key określimy w konstruktorze drzewa. Wyposażymy też klasę BinaryTree w metody insert_left(key) oraz insert_right(key) (głównie w celach demonstracyjnych), które tworzą nowy węzeł przechowujący klucz key i ustawiają węzeł jako lewe (odpowiednio prawe) dziecko korzenia. Dla każdej z funkcji musimy rozważyć dwa przypadki: jeśli korzeń nie ma jeszcze odpowiedniego dziecka, lub już je ma. Dla insert_left(key), przypadki wyglądają następująco (dla insert_right(key) sa one analogiczne):
t z wartością key i ustawiamy t jako lewe dziecko korzenia.t z wartością key, ustawiamy lewe poddrzewo korzenia jako lewe poddrzewo t, następnie ustawiamy t jako lewe dziecko korzenia.Poniżej pokazujemy implementację klasy BinaryTree uzupełnioną o dodatkowe metody służące do odczytywania atrybutów key, left, right oraz ustawienia nowego key.
class BinaryTree:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
def insert_left(self, key):
t = BinaryTree(key)
if self.left is None:
self.left = t
else:
t.left = self.left
self.left = t
def insert_right(self, key):
t = BinaryTree(key)
if self.right is None:
self.right = t
else:
t.right = self.right
self.right = t
def get_left_child(self):
return self.left
def get_right_child(self):
return self.right
def set_root_val(self, obj):
self.key = obj
def get_root_val(self):
return self.key
def __str__(self):
return f"[{self.key}; {self.left}; {self.right}]"
Powyższa implementacja zawiera jeszcze jedną metodę: __str__(). Napisowa reprezentacja drzewa przedstawia klucz jego korzenia oraz rekurencyjnie wyznaczone napisowe reprezentacje jego poddrzew (jeśli istnieją). W pliku binary_tree.py znajduje się jeszcze kompletniejsza implementacja, uzupełniona o funkcje pozwalające na trawersowanie drzewa. O trawersowaniu drzewa będzie traktować dalszy rozdział.
Poniżej przykładowe użycie drzewa:
r = BinaryTree('a')
print(r)
r.insert_left('b')
print(r)
r.get_left_child().insert_right('c')
print(r)
[a; None; None] [a; [b; None; None]; None] [a; [b; None; [c; None; None]]; None]
Drzewa wyrażeń arytmetycznych to drzewa binarne reprezentujące wyrażenie arytmetyczne. Drzewo takie ma jedną z dwóch postaci:
Przykładowo, poniższe drzewo reprezentuje wyrażenie $(a + b) \cdot c + 7$:
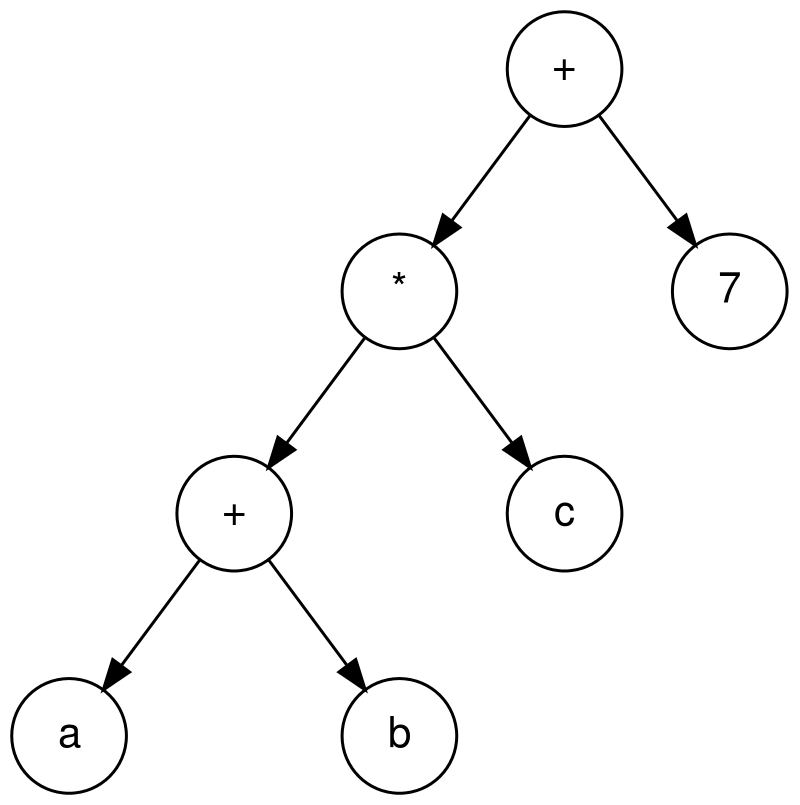
Obserwujemy następujące własności drzewa wyrażenia:
Naszym celem będzie napisanie dwóch algorytmów:
Uściślijmy, jakie wyrażenia będziemy konwertować do postaci drzewa wyrażeń. Będą to w pełni znawiasowane wyrażenia w notacji zwykłej (infiksowej). Oznacza to, że nawiasy kładziemy wokół każdego pełnego działania arytmetycznego, lecz nie wokół liczb i symboli. Przykładami w pełni znawiasowanych wyrażeń są:
( ( 10 + 5 ) * 3 )( 1 + ( 2 + ( 3 + 4 ) ) )100Wejściem dla algorytmu będzie ciąg tokenów. Istnieją cztery rodzaje tokenów: lewy nawias, prawy nawias, operator i argument (liczba lub symbol).
Podobnie jak przy konwersji wyrażeń do ONP (wykład 3), wymagamy obecności białych znaków między tokenami.
Kroki algorytmu parsowania drzewa. W każdym kroku pamiętamy węzeł, w którym działamy.
- Stwórz nowe drzewo
t. Aktualnym węzłem jest korzeń.- Dla kolejnych tokenów z wejścia:
2a. Jeśli token to '(': stwórz nowe, lewe dziecko aktualnego węzła i zstąp do niego.
2b. Jeśli token jest operatorem: ustaw wartość rodzica aktualnego węzła na wartość tokenu. Stwórz nowe, prawe dziecko rodzica węzła i przejdź doń.
2c. Jeśli token jest argumentem, ustaw wartość aktualnego węzła na wartość tokenu.
2d. Jeśli token to ')': wróć do rodzica aktualnego węzła.- Zwróć drzewo
t.
W algorytmie, rodzice węzłów pamiętamy, odkładając je na stos za każdym zstąpieniem w poddrzewo. W ten sposób zawartość stosu wraz z aktualnym węzłem stanowi ścieżkę z korzenia do aktualnego węzła.
Przykład: ( 1 + ( 2 * 3 ) ). Kolejne kroki algorytmu wyglądają następująco (czerwona kropka notuje aktualny węzeł drzewa):
| Wczytany token | Krok | Zbudowane drzewo po wykonaniu kroku |
|---|---|---|
| (początek algorytmu) | 1. Stwórz nowe drzewo, aktualnym węzłem jest korzeń. | 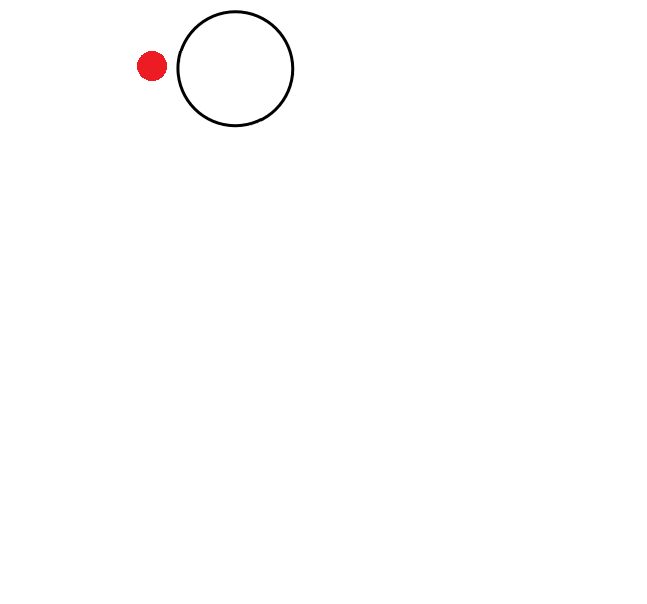 |
| ( | 2a. Stwórz nowe, lewe dziecko aktualnego węzła i zstąp do niego. | 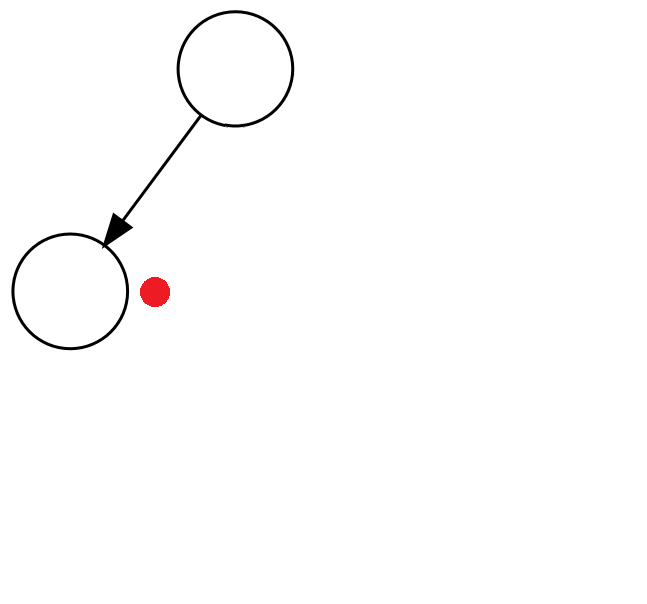 |
| 1 | 2c. Ustaw wartość aktualnego węzła na wartość tokenu. | 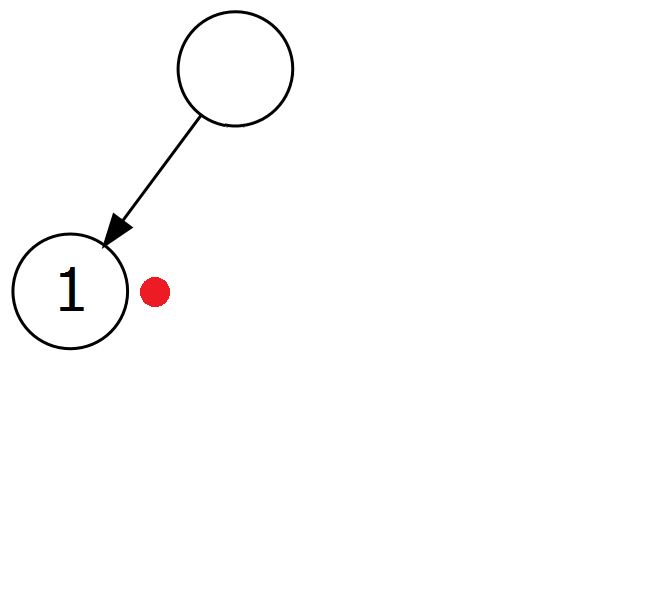 |
| + | 2b. Ustaw wartość rodzica aktualnego węzła na wartość tokenu. Stwórz nowe, prawe dziecko rodzica węzła i przejdź doń. | 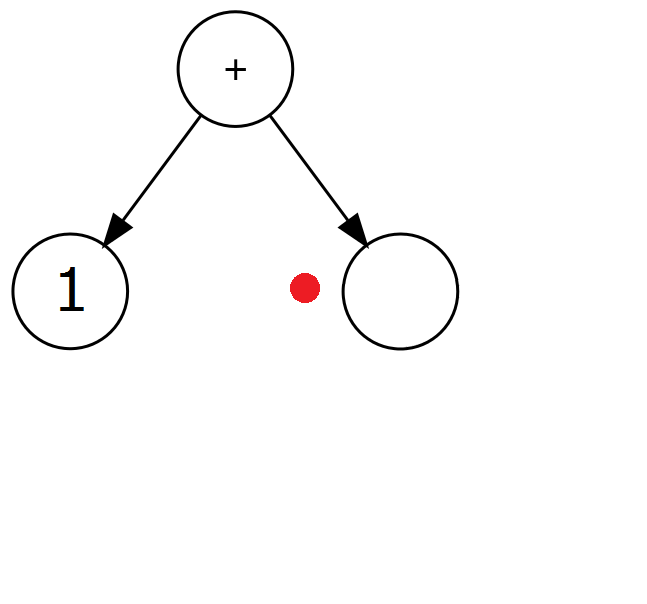 |
| ( | 2a. Stwórz nowe, lewe dziecko aktualnego węzła i zstąp do niego. | 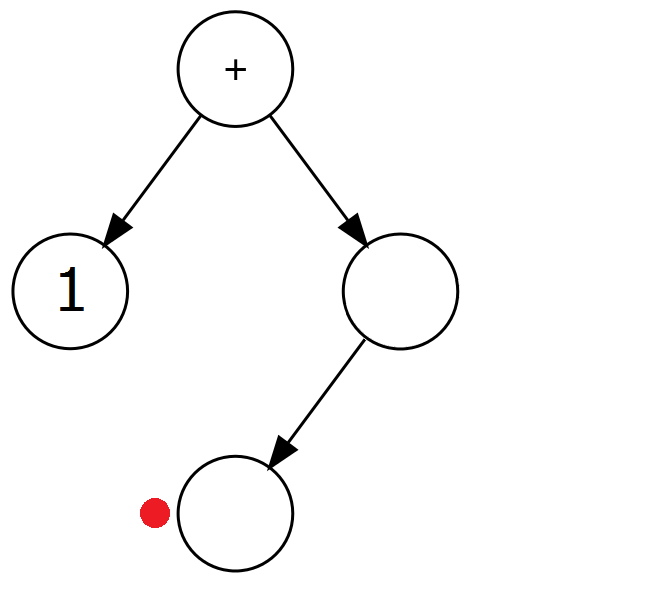 |
| 2 | 2c. Ustaw wartość aktualnego węzła na wartość tokenu. | 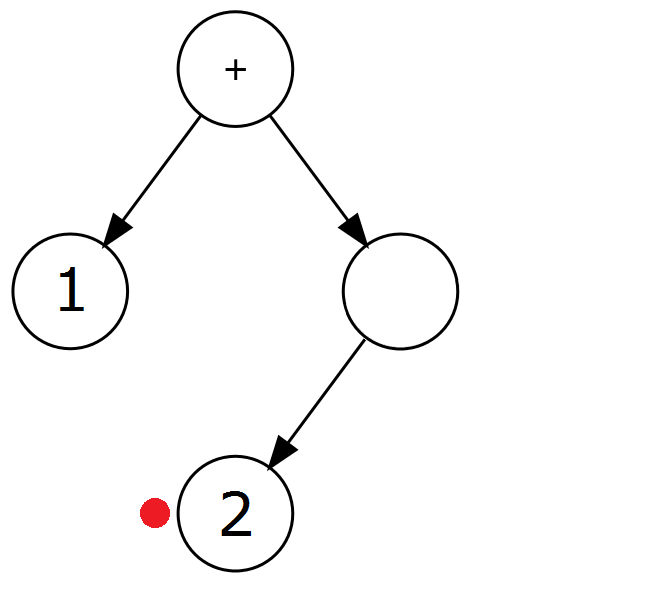 |
| * | 2b. Ustaw wartość rodzica aktualnego węzła na wartość tokenu. Stwórz nowe, prawe dziecko rodzica węzła i przejdź doń. | 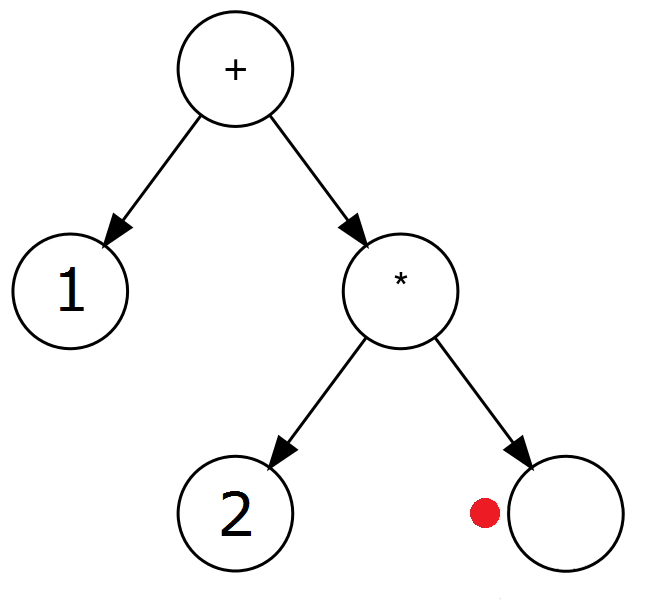 |
| 3 | 2c. Ustaw wartość aktualnego węzła na wartość tokenu. | 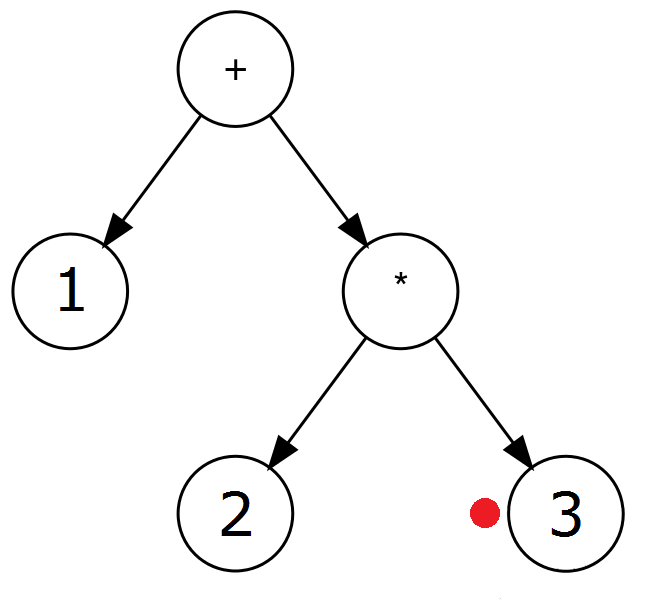 |
| ) | 2d. Wróć do rodzica aktualnego węzła. | 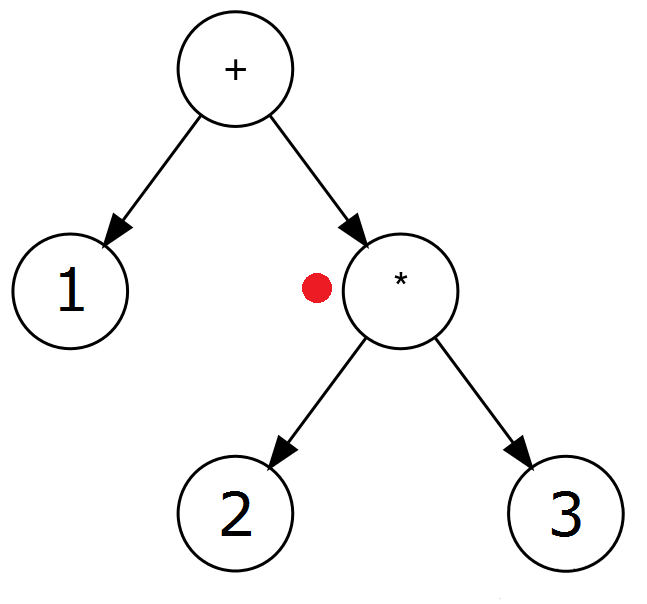 |
| ) | 2d. Wróć do rodzica aktualnego węzła. | 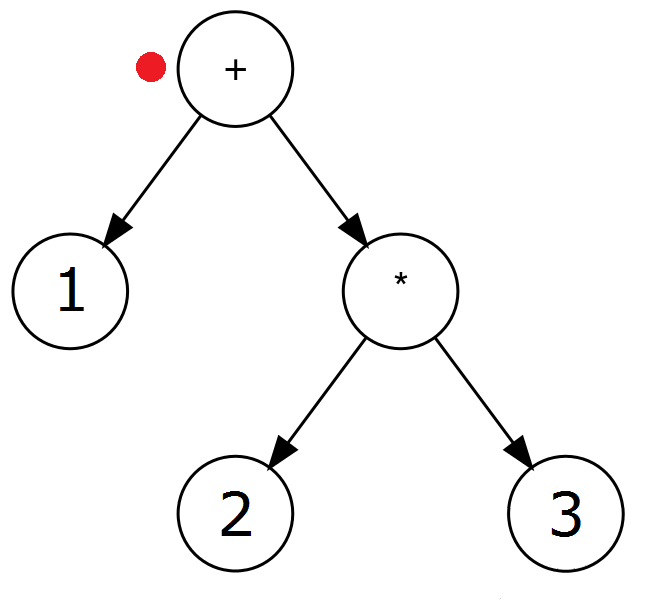 |
Ewaluacja drzewa reprezentującego wyrażenie jest prosta:
Zaimplementujemy klasę Parser (parsowanie - odczytywanie struktury podanego wejścia), której zadaniem jest zbudowanie drzewa podanego w konstruktorze wyrażenia. Klasa będzie posiadać metody do wyliczenia wartości tego wyrażenia i przedstawienia go z powrotem w postaci napisu.
Obiekt klasy Parser będzie miał następujące atrybuty:
tokens - lista tokenów rozważanego wyrażenia.ast - obiekt klasy BinaryTree: drzewo wyrażenia, które parser zbuduje.opers - atrybut klasy (nie instancji). Słownik stowarzyszający tokeny wyrażeń arytmetycznych z funkcjami, które je wykonują.Klasa ma też metody:
__init__(self, infix_expr) - tworzy instancję Parser, która parsuje podane w pełni znawiasowane wyrażenie w notacji infiksowej.make_ast(self) - metoda do użytku wewnętrznego, konstruuje drzewo ast z listy tokenów tokens.eval(self) - zwraca wartość drzewa wyrażenia (czyli wartość sparsowanego wyrażenia).print_exp(self) - zwraca napis, odpowiadający drzewu wyrażeń (wartość oryginalnego wyrażenia).Pełna implementacja Parser znajduje się w pliku parse_tree.py. Nie omówimy tutaj jej całej - zauważymy, że make_ast() to implementacja algorytmu opisanego w poprzednim podrozdziale, a eval() to podany wyżej algorytm ewaluacji. Zwrócimy jednak uwagę na pewne szczegóły implementacji.
operator to standardowy moduł Pythona, który zawiera funkcje odpowiadające operatorom arytmetycznym. Przykładowo, funkcja operator.add to funkcja dwóch argumentów, zwracająca ich sumę.opers stowarzysza tokeny oznaczające działania arytmetyczne z odpowiednimi funkcjami z modułu operator. Jego definicja wygląda następująco (jest on atrybutem klasy Parser):opers = {'*': operator.mul, '/': operator.truediv,
'+': operator.add, '-': operator.sub}
Parser.opers['+'](2, 3) # == 2 + 3
opers jest używany w metodzie eval():return Parser.opers[tree.get_root_val()](res1, res2)
tree.get_root_val() jest operatorem z korzenia drzewa tree, zaś res1 i res2 to wartości lewego i prawego poddrzewa tree odpowiednio.Trawersowanie drzewa to proces polegający na odwiedzeniu jego węzłów w pewnej ustalonej kolejności. Odwiedzenie węzła polega na wykonaniu operacji na obiekcie, który ten węzeł przechowuje (na przykład obiekt można wypisać).
Dla drzew binarnych, wyróżniamy trzy sposoby trawersowania. Każdy ze sposobów polega na odwiedzeniu korzenia drzewa, oraz rekurencyjnym trawersowaniu jego lewego i prawego poddrzewa (jeśli istnieją). Są to sposoby preorder, inorder oraz postorder.
Ściślej, opiszemy kroki trzech algorytmów:
Kroki
preorder(wejście: drzewo/węzełT):
- Odwiedź węzeł
T.- Odwiedź lewe poddrzewo
Talgorytmempreorder. 3.Odwiedź prawe poddrzewoTalgorytmempreorder.
Kroki
inorder(wejście: drzewo/węzełT):
- Odwiedź lewe poddrzewo
Talgorytmeminorder.- Odwiedź węzeł
T. 3.Odwiedź prawe poddrzewoTalgorytmeminorder.
Kroki
postorder(wejście: drzewo/węzełT):
- Odwiedź lewe poddrzewo
Talgorytmempostorder.- Odwiedź prawe poddrzewo
Talgorytmempostorder.- Odwiedź węzeł
T.
Dla drzewa wyrażenia ( 1 + ( 2 * 3 ) ), które skonstruowaliśmy w poprzednim rozdziale, algorytmy trawersują węzły w następującej kolejności:
preorder: + 1 * 2 3inorder: 1 + 2 * 3postorder: 1 2 3 * +Można zwrócić uwagę, że kolejne tokeny uzyskane przy trawersowaniu preoder układają się w wyrażenie NP równoważne oryginalnemu wyrażeniu. Podobnie, tokeny kolejno uzyskane przy trawersowaniu postorder układają się w odpowiednie wyrażenie ONP. Natomiast te uzyskane algorytmem inorder to oryginalne wyrażenie infiksowe, jednak pozbawione nawiasów. Fakty te uogólniają się na wszystkie drzewa wyrażeń.
Algorytmy preoder, inorder i postorder zostały zaimplementowane w klasie BinaryTree jako metody. Odwiedzanie węzła polega na wypisaniu wartości, którą przechowuje.
Drzewo wyszukiwań binarnych to szczególny rodzaj drzewa binarnego, w którego węzłach przechowujemy parami porównywalne elementy (według pewnego praporządku).
Definicja. Drzewo binarne $(V, S)$ jest drzewem wyszukiwań binarnych wtedy, gdy dla każdego węzła $x \in V$, obiekt przechowywany w $x$ jest nie mniejszy od obiektów przechowywanych w węzłach lewego poddrzewa $x$, i nie większy od obiektów przechowywanych w węzłach prawego poddrzewa $x$.
Rysunek poniżej przedstawia przykład drzewa wyszukiwań binarnych, którego węzły przechowują liczby:

Jak widzimy, korzeń drzewa przechowuje wartość 8, która jest nie mniejsza od wartości przechowywanym w lewym poddrzewie korzenia (te wartości to 1, 3, 4, 6 i 7), ale nie większa od wartości przechowywanych w prawym poddrzewie (10, 13 i 14). Podobnie dla węzła przechowującego 3, jego lewe poddrzewo przechowuje wartość 1, a prawe poddrzewo 4, 6 i 7.
Przedstawimy teraz algorytm umieszczania w drzewie wyszukiwań binarnych nowego węzła o zadanych wartości, a następnie algorytm efektywnego sprawdzania, czy w drzewie znajduje się podana wartość. W obu algorytmach korzystamy z rekurencyjnego opisu drzew, w którym drzewo składa się z korzenia i swoich poddrzew.
W najprostszym wariancie, nowy elementy dokładany jest jako nowy liść danego drzewa tak, aby drzewo pozostało binarnym drzewem poszukiwań. Możliwe jest, że elementy równe dokładanemu znajdują się już w drzewie.
Niech $T$ będzie drzewem, w którego korzeniu przechowywany jest obiekt $x$. Do drzewa chcemy dodać element $y$. Rozpatrzmy przypadki:
Powyższy opis jest dobrym schematem rekurencyjnego postępowania: we wszystkich przypadkach następuje redukcja problemu: dołożenia nowego liścia, lub dołożenia elementu do mniejszego drzewa. Stąd rekurencyjny opis algorytmu:
Kroki algorytmu
insert(T- drzewo/węzeł,key- nowy obiekt do wstawienia):
- Jeśli
keyjest mniejszy lub równy obiektowi wT:
1a. Jeśli korzeń nie ma lewego poddrzewa, dodaj do korzenia nowe lewe dziecko z obiektemkey.
1b. W przeciwnym wypadku, wykonajinsertdla lewego dzieckaTikey.- Jeśli
keyjest większy od obiektu wT:
2a. Jeśli korzeń nie ma prawego poddrzewa, dodaj do korzenia nowe prawe dziecko z obiektemkey.
2b. W przeciwnym wypadku, wykonajinsertdla prawego dzieckaTikey.
Wyszukiwanie elementu realizujemy na podobnej zasadzie, co wstawianie elementu: poprzez redukcję problemu do poddrzew. Niech $T$ będzie drzewem, w którego korzeniu znajduje się obiekt $x$. Chcemy rozstrzygnąć, czy w $T$ znajduje się węzeł przechowujący obiekt $y$. Rozważmy przypadki:
Stąd naturalny algorytm:
Kroki algorytmu
search(T- drzewo/węzeł,key- szukany obiekt):
- Jeśli
keyjest równy obiektowi wT: zwróć TAK.- Jeśli
keyjest mniejszy od obiektuT:
2a. Jeśli korzeń nie ma lewego poddrzewa, zwróć NIE.
2b. W przeciwnym wypadku, wykonajsearchdla lewego dzieckaTikeyi zwróć jego wynik.- Jeśli klucz jest większy od obiektu w
T:
3a. Jeśli korzeń nie ma prawego poddrzewa, zwróć.
3b. W przeciwnym wypadku, wykonajinsertdla prawego dzieckaTikeyi zwróc jego wynik.
Kod drzew wyszukiwań binarnych znajduje się w pliku bst.py. Jego kluczowa część wygląda następująco:
class BinarySearchTree:
def __init__(self, key):
self.key = key
self.left = None
self.right = None
def insert(self, key):
if key <= self.key:
if self.left:
self.left.insert(key)
else:
self.left = BinarySearchTree(key)
else:
if self.right:
self.right.insert(key)
else:
self.right = BinarySearchTree(key)
def search(self, key):
if self.key == key:
return True
if key < self.key:
if not self.left:
return False
return self.left.search(key)
if not self.right:
return False
return self.right.search(key)
Atrybuty key, left i right mają to samo znaczenie, co w zwykłych drzewach binarnych. Metody insert(key) i search(key) implementują algorytmy opisane w dwóch poprzednich podrozdziałach. Implementacja w pliku bst.py zawiera dodatkowe metody, między innymi służące do trawersowania drzewa.
Fakt 2. Trawersowanie drzewa w porządku inorder odwiedza obiekty w kolejności niemalejącej.
Powyższy Fakt ma konsekwencje dla pewnych algorytmów sortowań.
Rozważmy teraz zastosowanie drzew wyszukiwań binarnych jako zbioru (lub ściślej: multizbioru, czyli "zbioru", który może zawierać wiele takich samych elementów). W tym celu zastanówmy się nad czasem algorytmów insert i search. Zauważamy, że:
Patrząc inaczej: oba algorytmy odwiedzają kolejne węzły na jednej z gałęzi drzewa.
Wniosek. Złożoność
searchiinsertjest liniowa ze względu na wysokość drzewa.
Rozważmy teraz, jaka może być wysokość drzewa binarnego o $n$ wierzchołkach.
Fakt 3. W "średnim" przypadku (np. drzewa binarnego, do którego włożono klucze wybierane losowo i niezależnie z przedziału $[0, 1]$ z prawdopodobieństwem jednostajnym), wysokość drzewa o $n$ węzłach to $\Theta(\log n)$.
Fakt stwierdza, że "średni" przypadek przypomina przypadek optymistyczny. Więcej o "średnim" przypadku, a także specjalnych rozdzajach drzew binarnych gwarantujących logarytmiczną wysokość (względem ilości węzłów) powiemy w dalszej części semestru.
Łącząc Wniosek z powyższym Faktem, otrzymujemy:
Stwierdzenie. Dla typowego binarnego drzewa wyszukiwań, algorytmy
searchiinsertdziałają w czasie $\Theta(\log n)$.