G. Jagiella | ostatnia modyfikacja: 16.03.2021 |
Wykład 4 (cz. 1) - iteratory i generatory¶
Wstęp¶
Obiekty iterowalne reprezentują ciągi obiektów. Przez obiekty iterowalne można iterować: przykładami są pętle for, konstrukcje list lub słowników składanych; wiele metod lub funkcji z bibliotek standardowych (i nie tylko) jest napisanych tak, aby ich parametrami były dowolne obiekty iterowalne (np. w matplotlib: plot(range(1, 5), [1, 2, 4, 5])). W tym rozdziale opiszemy techniczną stronę iteracji w Pythonie, w szczególności jak implementować obiekty iterowalne.
Szybko poczyńmy obserwację, że obiekty reprezentowane przez obiekt iterowalny nie muszą być obecne w pamięci cały czas, nawet gdy nie są potrzebne. W przypadku kolekcji takich jak list czy set, obiekty przez które iterujemy to zawartość kolekcji - obiekty te istnieją w pamięci. Z drugiej strony, obiekt range reprezentuje ciąg arytmetyczny liczb całkowitych. Te liczby są tworzone i umieszczane w pamięci dopiero w momencie, gdy napotykamy je iterując przez range. Stąd np. range(100), range(10000) i range(0, 10**10, 100) zajmują (mówiąc w niewielkim uproszczeniu) taką samą ilość pamięci, bo pamiętają jedynie początek, koniec i krok ciągu.
Iteratory obiektów¶
Niech obj będzie iterowalnym obiektem. W iterowaniu przez obj uczestniczą w rzeczywistości dwa obiekty:
- Sam obiekt
obj. - Jego iterator.
Czynimy tutaj następujące obserwacje i uwagi:
- Nasza jedyna bezpośrednia interakcja z Biblioteką to wywołanie z niej Bibliotekarza. Potem badanie książek z Biblioteki wykonuje się wyłącznie za jego pośrednictwem.
- Nie interesuje nas, w jaki sposób Bibliotekarz pozyskuje kolejne podawane tytuły książek. Może zna je po kolei na pamięć. Może za każdym razem, gdy go pytamy, biegnie do Biblioteki i sprawdza. Może zmyśla.
- Nie mamy gwarancji, że gdy rozpoczniemy nowy przegląd Biblioteki, to wyjdzie z niej ten sam Bibliotekarz. Co więcej, Biblioteka może być przeglądana przez wielu ludzi naraz, każdy obsługiwany przez innego Bibliotekarza.
- Jako niuans: jest nawet gorzej - wielu ludzi może pytać tego samego Bibliotekarza, a on nie odróżnia pytających - więc będzie zawsze podawał tytuł następnej książki.
Iteracje w Pythonie przebiegają na podobnej zasadzie, jak przegląd Biblioteki. Biblioteka to obiekt iterowalny obj, Bibliotekarz to jego iterator. Przegląd biblioteki to iteracja.
Bardziej formalnie: iterator to obiekt dostarczany przez obj na potrzeby konkretnej iteracji (dla uproszczenia przyjmijmy, że tą iteracją jest pętla for x in obj). Iterator pamięta, że jest iteratorem obj. Służy do księgowania, jaki element (obiekt) obj ma zostać obsłużony w kolejnych obrotach pętli. Aby przebiegać przez elementy obj, pętla komunikuje się z iteratorem (nie z samym obiektem!). W każdym obrocie pętli, z iteratora pobierany jest element, który (w tym przykładzie) zostaje nazwany x. Zamiast podać obiekt, iterator może zgłosić, że nie ma już dalszych obiektów; pętla jest wtedy kończona.
Zilustrujmy ten proces na konkretnym przykładzie:
for x in ['a', 'b', 'c']:
print(x)
Tutaj obj jest typu list i składa się z trzech obiektów.
Proces iterowania przebiega wtedy następująco (kolejne kroki):
- Początek iteracji: od
objzostaje zażądany iterator.objgo podaje: oznaczmy goit. - Pierwszy obrót pętli: od
itżądany jest obiekt.itpodaje pierwszy elementobj, czyli'a'. 'a'nazywane jestx, wykonujemy treść pętli (print(x)).- Drugi obrót pętli: powtarzają się kroki 2-3, ale tym razem elementem podanym przez
itjest'b'. - Trzeci obrót pętli: jak wyżej, dla elementu
'c'. - Pętla, chcąc rozpocząć czwarty obrót, żąda obiektu od
it.itnie może już podać obiektu, zgłasza koniec iteracji, pętla się kończy.
W ogólności, obiekty podawane przez iterator nie muszą być przypisywane do nazwy w pewnej pętli (po czym następuje wykonanie treści pętli), ale np. przekazywane funkcji lub wyrażeniu, którego wartość jest dokładana do listy w schemacie listy składanej, np. [x**2 for x in range(5)]. Takie "obsłużenie" obiektu podanego w kolejnych obrotach iteracji nazwiemy skonsumowaniem go. Ogólny schemat iteracji po obj można wtedy opisać następująco:
- Najpierw
objdostarcza iteratorit. - Od
itżądany jest obiekt. Jeśliitnie podaje obiektu, pętla się kończy. W przeciwnym wypadku podany obiekt jest konsumowany. - Wróc do kroku 2.
W Pythonie, aby obj był rozpoznany jako obiekt iterowalny, on i jego iteratory muszą realizować protokół iteratorów. Konkretnie:
- Obiekt iterowalny
objmusi implementować metodę specjalną__iter__(), zwracającą iterator. - Iterator musi implementować metodę
__next__(), która albo zwraca obiekt do skonsumowania, albo rzuca wyjątekStopIteration, reprezentujący koniec iteracji; oraz metodę__iter__(), zwracającą iterator (może nim być - i zazwyczaj jest - on sam).
Python ma wbudowane funkcje iter() i next(), które przyjmują obiekt jako parametry. Wywołanie iter(obj) tłumaczy się na wywołanie obj.__iter__(), analogicznie dla next(obj). Możemy użyć tych funkcji do przeprowadzenia iteracji "krok po kroku", jak w przykładzie powyżej. Najpierw stwórzmy listę do iterowania:
lst = ["a", "b", "c"]
Weźmy iterator listy:
it = iter(lst)
Zbadajmy tekstową reprezentację iteratora i jego typ:
print(str(it))
print(type(it))
Widzimy stąd, że obiekt typu list zwraca jako iterator obiekt typu list_iterator.
Kolejne wywołania next(it) będą zwracać kolejne elementy z listy, która zwróciła ten iterator. Wypiszmy trzy obiekty zwracane przez next(it):
print(next(it))
print(next(it))
print(next(it))
Iterator wyczerpał elementy listy, więc następne wywołanie rzuci wyjątek StopIteration:
try:
next(it)
except StopIteration:
print('StopIteration rzucony!')
Powyższy proces na ilustracji:

Obiekt może uczestniczyć w więcej niż jednej iteracji: każda iteracja ma swój iterator. Przykładowo:
lst = ['a', 'b', 'c']
it = iter(lst)
print(next(it)) # 'a'
it2 = iter(lst)
print(it is it2) # False
print(next(it2)) # znowu 'a'
print(next(it)) # 'b'
print(next(it)) # 'c'
print(next(it2)) # 'b'
Podobnie, w poniższym kodzie:
lst = [1, 2, 3]
for x in lst:
for y in lst:
print(x, y)
występują cztery iteracje, a więc pojawiają się cztery niezależne od siebie iteratory. Zauważmy, że gdyby stan iteracji po obiekcie był zapisany w samym obiekcie (np. gdyby to sama lista lst pamiętała, jaki obiekt został ostatnio przekazany do skonsumowania), to w powyższym przykładzie iteracja w pętli "zewnętrznej" konfliktowałaby z iteracjami w pętlach "wewnętrznych".
Przykład. Omówimy teraz, w jaki sposób iterator listy (obiekt typu
list_iterator) śledzi wewnętrznie stan iteracji. Iterator taki pamięta dwie informacje: listę, z którą jest stowarzyszony i indeks elementu, który ma być zwrócony nastepnym razem, gdy od iteratora zostanie zażądany element do skonsumowania przez iterację. Początkowo indeks ma wartość0. Gdy iterator ma podać następny element, jeśli indeks jest legalny (mniejszy niż rozmiar listy), iterator zwraca element z listy o tym indeksie i zwiększa indeks o1. W przeciwnym wypadku rzucaStopIteration. To prowadzi do następującego (niekoniecznie zgodnego z intuicją) działania pętli poniżej:
lst = list(range(6))
for x in lst:
print(x)
lst.remove(x)
print('lista po iteracji:', lst)
Po kolei: początkowo lista
lstma postać[0, 1, 2, 3, 4, 5]. W pierwszym obrocie pętli, iterator zwraca element spod indeksu0, czyli0, który zostaje wypisany a następnie usunięty z listy. Wtedy lista ma postać[1, 2, 3, 4, 5]. W następnym obrocie pętli, iterator zwraca obiekt spod indeksu1, a jest nim2- zostaje on wypisany i usunięty. Proces się powtarza i w rezultacie pętla wykonuje trzy obroty, a nalstpozostają elementy pominięte w iteracji.
Z powodu takiego zachowania iteratorów listy, poniższa pętla nigdy się nie skończy:lst = [1] for x in lst: lst.append(1)
Szereg wbudowanych kolekcji Pythona to obiekty iterowalne. Zbadajmy typy ich iteratorów:
for t in (list, tuple, str, set, dict):
obj = t() # nowy obiekt typu list, tuple, ...
it = iter(obj) # jego nowy iterator
print(type(it))
print(type(iter(range(0)))) # nie można range(), można range(0)
Obserwujemy tutaj konwencję nazewniczą, jaką Python stosuje dla iteratorów wbudowanych typów. Zwróćmy uwage na iterator słownika: dict_keyiterator, z nazwą sugerującą, że iterator służy do iterowania po kluczach słownika. Rzeczywiście, pętla iterująca po słowniku iteruje po jego kluczach:
d = {'a': 1, 'b': 2, 'c': 42}
for k in d:
print(k)
Słowniki mają jednak metody, które zwracają iterowalne obiekty reprezentujące wartości oraz pary klucz-wartość:
values = d.values()
print(type(values), type(iter(values)))
items = d.items()
print(type(items), type(iter(items)))
# Poniżej iterujemy po d.items(), zwrócone obiekty są konsumowane przez konstruktor listy
print(list(d.items()))
Iterator dla stosu z wykładu¶
W tym podrozdziale uzupełnimy klasę (typ) Stack z wykładu o iterator. Zaimplementujemy iterator w taki sposób, aby zwracał kolejne obiekty ze szczytu stosu, za każdym razem usuwając je ze stosu. Jako bazowy weźmiemy następujący kod stosu - dla prostoty usunęliśmy z niego część metod:
# Okrojona wersja oryginalna
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
Zasada iteratora stosu będzie prosta: iterator pamięta stos, do iteracji którego służy. W momencie, gdy jest proszony o zwrócenie elementu, sprawdza czy stos jest pusty. Jeśli tak, rzuca StopIteration aby zakończyć iterację. Jeśli nie, ściąga ze stosu element i zwraca go. Przypomnijmy: zachowanie iteratora, od którego zażądano elementu, jest zadane przez implementację metody specjalnej __next__(). Stwórzmy zatem klasę StackIterator, iterator dla typu Stack:
class StackIterator:
def __init__(self, stack):
self.stack = stack
def __iter__(self): # wymaganie protokołu
return self
def __next__(self):
if self.stack.is_empty():
raise StopIteration
return self.stack.pop()
Klasa zawiera konstruktor (inicjalizator), w którym zostanie zapamiętany stos, który zwraca iterator. Teraz zmodyfikujemy klasę Stack, dodając metodę __iter__() tak, aby zwracała nowy obiekt StackIterator, pamiętający sam stos:
# Wersja z __iter__()
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __iter__(self):
return StackIterator(self)
Przetestujmy działanie iteratora na dwa sposoby.
Iterator stosu - pętla¶
Tutaj prezentujemy sposób, w jaki zazwyczaj iterowalibyśmy po stosie:
s = Stack()
s.push('a')
s.push('[]')
s.push('!')
for el in s:
print(el)
print(s.is_empty())
Iteracja wyczerpała obiekty ze stosu (jest pusty po zakończeniu iteracji), przebiegliśmy przez stos od szczytu do spodu.
Iterator stosu - krok po kroku¶
Wykonamy iterację krok po kroku, wywołując iter() i next() na stosownych obiektach (jak dla list w poprzednim podrozdziale). Zaczynamy od stworzenia stosu i wzięcia iteratora:
s = Stack()
s.push('a')
s.push([])
s.push('!')
it = iter(s)
print(type(it))
Nazwa klasy iteratora jest udekorowana nazwą modułu, w którym się znajduje (tutaj jest to moduł główny). Kontynuujemy:
print(next(it))
print(s.items)
Skonsumowaliśmy obiekt ze szczytu stosu, a sam obiekt z niego zniknął.
print(next(it))
print(s.items)
print(next(it))
print(s.items)
Stos jest już pusty - następny next(it) rzuci wyjątek.
Iteratory bez obiektu¶
Wiemy, że za wyjątkiem otrzymania iteratora od obiektu, po którym iterujemy, iteracja nie prowadzi interakcji z samym obiektem, a z jego iteratorem. Można zatem zapytać, czy można mieć iterator bez obiektu i wykonywać iterację przy jego pomocy. Rzeczywiście, można, a rozwiązanie jest dosyć proste - wystarczy zaimplementować iterator (obiekt z metodą __next__()), który jest jednocześnie swoim własnym iteratorem.
Przykład takiego iteratora - uproszczony odpowiednik count z modułu itertools, który przebiega po kolejnych liczbach naturalnych (nigdy nie rzucając StopIteration - iteracja nigdy się nie kończy, o ile jej nie przerwiemy!):
class Count:
def __init__(self):
self.n = -1
def __next__(self):
self.n += 1
return self.n
def __iter__(self):
return self
Przykładowe użycie:
for n in Count():
print(n)
if n == 5:
break
Tutaj iterujemy po nowo utworzonym obiekcie typu Count. Zaczynając iterację, dostajemy jego iterator - jest to ten sam obiekt, na którym w każdym obrocie pętli jest wywoływany __next__(), zwracający kolejne liczby naturalne.
Sytuacja, w której iterator jest iterowalny i tożsamy ze swoim iteratorem jest dość typowa: np. dla obiektów wbudowanych mamy:
lst = [1, 2, 3]
it = iter(lst)
print(it is iter(it))
Generatory¶
Szczególnym przypadkiem iteratorów sa generatory: wartości podawane przez nie w iteracji są generowane "na bieżąco" (leniwie). W Pythonie mamy dwa rodzaje generatorów: stworzone przez funkcje generujące i przez wyrażenia generujące, które teraz opiszemy.
Funkcje generujące¶
Rozważmy funkcję, która wypisuje (w nieskończoność) kwadraty kolejnych liczb naturalnych, zaczynając od zadanej:
def print_quads(start):
n = start
while True:
print(n ** 2)
n += 1
Czasem wygodnie byłoby po prostu mieć iterator, który przebiega przez kolejne kwadraty. Mając funkcję quads, która zwraca taki hipotetyczny iterator, możnaby go użyć następująco:
for x in quads(5):
print(x)
Lub w dowolny inny sposób:
s = 0
for x in quads(10):
s += x
if x > 15:
break
Jednym sposobem byłoby zmodyfikowanie klasy Count z poprzedniego podrozdziału. Jest jednak lepszy sposób, który pozwala na zmodyfikowanie funkcji print_quads w taki sposób, aby zamiast wypisywać kolejne wartości, zwracała po prostu iterator, który przez nie przebiega. Posłuży do tego słowo kluczowe yield.
Funkcja, w której pojawi się słowo yield przestaje być zwykłą funkcją, a zmienia się w tzw. funkcję generującą. Taka funkcja nie wywołuje się w zwykły sposób. Zamiast tego, wywołanie jej tworzy generator - rodzaj iteratora. Instrukcja yield służy do podania obiektu, który ma zostać zwrócony podczas pojedynczego obiegu iteracji (np. yield x). Pierwsze wywołanie next() na generatorze powoduje wykonanie treści funkcji aż do napotkania instrukcji yield, po której następuje obiekt, który zostanie zwrócony przez iterator. Instrukcja yield, w odróżnieniu od return, zamiast kończyć, jedynie zawiesza działanie funkcji i przekazuje kontrolę do miejsca, w którym użyte zostało next(). Stan zmiennych lokalnych funkcji zostaje zapamiętany. Przy następnym i kolejnych wywołaniach next(), działanie funkcji zostanie wznowione od miejsca, w którym ostatnio natrafiono na yield, aż do napotkania następnej instrukcji yield.
W każdej z powyższych sytuacji wywołania next(), jeśli treść funkcji się skończy (lub napotkane zostanie return), generator nie zwróci obiektu i rzuci StopIteration.
Posłużymy się przykładem - niewielką modyfikacją print_quads:
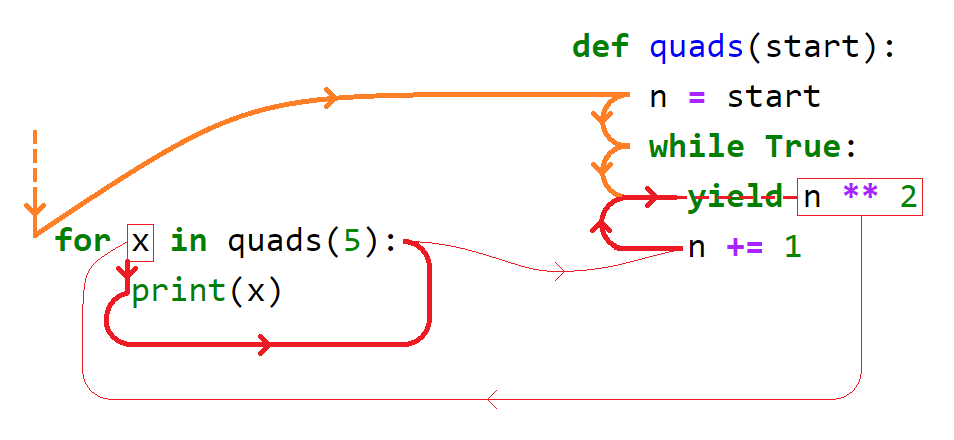
1| def quads(start):
2| n = start
3| while True:
4| yield n ** 2
5| n += 1
6|
7| for x in quads(5):
8| print(x)
Prześledzimy krok po kroku, jak wykonuje się ten kod (dobrze skorzystać tutaj z http://pythontutor.com/visualize.html). Numer kroku nie odpowiada numerowi omawianej linjki.
- W linijce 1 definiujemy funkcję generującą.
- Następnie w linijce 7 pojawia się
quads(5), które tworzy nowy generator - oznaczmy goobj(w kodzie występuje anonimowo). - Wciąż linijka 7: od
objżądamy jego iteratora przeziter(obj), jest nim samobj. - Pierwszy obieg pętli
for: wywołuje sięnext(obj). Wywołujemyquadsz parametremstart=5(zgodnie z parametrem konstrukcjiquads(5)). - W wywołaniu
quads: wykonują się linijki 2 i 3, zmienna lokalnanma wartość5. W linijce 4 mamyyield n ** 2. Funkcja zawiesza działanie (zn=5), wywołanienext(obj)z kroku 4 zwraca25. - Kontrola kodu wraca do linijki 7.
25jest konsumowane: zostaje nazwanex. Przechodzimy do treścifor. - Wykonuje się linijka 8,
25zostaje wypisane na ekran. - Następny obieg pętli
for. Wywołujemynext(obj). Wracamy doquadsw miejscu, w którym ostatnio z niej wyszliśmy, z takim samym stanem zmiennych lokalnych. - W treści
quads: wznawiamy wykonanie od linijki 5. Zwiększamyno1, które teraz ma wartość6. Koniec obrotuwhile. - Następny obrót
whileprzenosi nas do linijki 4. W linijce 4 mamyyield n ** 2. Funkcja zawiesza działanie (zn=6), wywołanienext(obj)z kroku 8 zwraca36. - Kontrola kodu wraca do linijki 7.
36jest konsumowane: zostaje nazwanex. Przechodzimy do treścifor. - Wykonuje się linijka 8,
36zostaje wypisane na ekran.
Następnie kroki 8-12 powtarzają się cyklicznie dla coraz większych n. Zaobserwujmy, że ograniczając uwagę do instrukcji z wnętrza quads, funkcja wykonuje się w zwykły sposób, instrukcja po instrukcji: yield powoduje czasowe przekazanie kontroli poza funkcję.
Przebieg kontroli sterowania w tym przykładzie na ilustracji:
Używając funkcji generującej, możemy bardzo zgrabnie napisać iterator stosu z wykładu:
# Wersja z generatorem - bez klasy StackIterator!
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return self.items == []
def push(self, item):
self.items.append(item)
def pop(self):
return self.items.pop()
def __iter__(self):
while not self.is_empty():
yield self.pop()
Tutaj metoda __iter__() jest funkcją generującą, yield-ującą kolejne elementy z wierzchu stosu aż do wyczerpania. Wywołanie iter() na stosie zwróci genreator zbudowany przez tę funkcję.
Wyrażenia generujące¶
Podobnie jak funkcje mogą zostać utworzone w sposób anonimowy przy użyciu wyrażeń lambda, również generatory można utworzyć przez krótkie wyrażenia generujące. Wyrażenia takie mają postać podobną do list składanych, ale zamiast tworzyć listę, tworzą generator leniwie zwracające kolejne obiekty. Przykładowo, listę pierwszych pięciu kwadratów możemy skonstruować jako listę składaną:
lst = [n**2 for n in range(5)]
Analogiczne wyrażenie generujące jest następującej postaci:
gen = (n**2 for n in range(5))
gen2 = (n**2 for n in range(5))
for x in gen:
print(x)
print('koniec pętli 1 (gen)')
for x in gen2:
print(x)
print('koniec pętli 2 (gen2)')
for x in gen2:
print(x)
print('koniec pętli 3 (gen2)')
Zwróćmy uwagę, że trzecia pętla for nic nie wypisała: pierwsza skonsumowała już wszystkie liczby, które generator wyprodukował. Podobny "destruktywny" charakter mają na przykład pliki: iterowanie po pliku konsumuje linijki. Zatrzymanie iteracji i rozpoczęcie nowej zaczyna od pierwszej nieskonsumowanej linijki.